После месяца ожидания, мой третий пул реквест был принят в node.js - https://github.com/nodejs/node/pull/27978 Теперь в node.js появится новый метод который позволит посмотреть сколько памяти нода выделяет под хранения кода и метаданных.
среда, 31 июля 2019 г.
пятница, 19 июля 2019 г.
Microsoft SLB (Software Load Balancing)
Кроме довольно убого NLB про которого я писал в прошлый раз, Microsoft сейчас предлагает SLB - Software Load Balancer. На мой взгляд этот балансер сделан гораздо более продумано. Но в данном случае название(Software) не отображает принципов работы этого балансировщика. В основе работы SLB лежат сетевые технологии, хотя некоторое количество серверного ПО конечно используется.
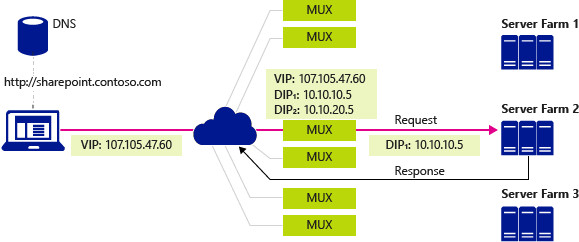
Если кратко то SLB использует BGP для балансировки запросов между несколькими MUX-ами (ECMP - Equal Cost Multi Path). Далее каждый MUX инкапсулирует клиентский IP пакетик в UDP пакетик (VXLAN) и отправляет их на железный сервер на котором запущена нужная виртуалка(виртуалки с нужным DIP - destinition IP). Далее железный сервер открывает пакет, в оригинальном IP пакете заменяет Destinition IP на DIP и передает его на сетевой интерфейс виртуалки. Виртуалка обрабатывает IP пакет, отвечает на него. И хост машина снова перехватывает IP пакет, и заменяет source IP на VIP (IP балансера). Таким образом клиент не знает истинного IP сервера, и следующий IP пакет тоже прийдет на балансер (VIP).
Еще из интересного - Microsoft научила MUX-ы пирится со свичами по BGP протоколу, так что они сами себя анонсируют. В общем из минусов на вскидку вижу только оверхед на VXLAN инкапсуляцию и расходы на NAT. Но от этого никуда не денешься.
четверг, 18 июля 2019 г.
Microsoft NLB
Я тут внезапно осознал еще одну особенность которая меня выбешивает в продуктах компании Microsoft. Они всегда используют общие термины для обозначения своих продуктов. К примеру- как называется MS SQL ? В документации Microsoft он всегда называется просто SQL Server. Как будто других SQL серверов вовсе нет. Поэтому когда говоришь о MS SQL всегда приходится уточнять - ты говоришь именно о Microsoft SQL Server, а не в общем обо всех серверах. Этим они убивают двух зайцев, во первых они "приватизируют" общие термины, во вторых они повышают упоминаемость своего брэнда. Ты как идиот вынужден всегда повторять название компании. С именованием балансировщика они придерживались такой же схемы. Я как идиот требовал от админов название софта который используется для балансировки - а они как попугаи повторяли - NLB, NLB. Я раза с третьего понял что NLB - это не какой-то абстрактный сетевой балансер, а прям вот такая "технология" microsoft.
На мой взгляд NLB это такой образец софта который круто выглядит с точки зрения маркетинга и презентации - а с точки зрения сетевых технологий и того как он реализуется - это просто жесть. Собственно принцип работы NLB состоит в том что все IP пакеты идущие от клиента к серверам дублируются на L2 уровне. Как будто вместо свитчей у нас тупые хабы. Для тех кто не так стар поясню что hub - это примитивная версия свитча, которая каждый пакет поступающий на любой из его портов рассылает на все другие порты. Современный свитчи знают к какому порту у них подключен какой mac адрес и посылают пакет именно туда. Таким образом каждый подключенный к свитчу сервер может пользоваться физическим носителем (оптика/витая пара) так как будто других серверов нет. В общем microsoft придумала технологию которая превращает свитч обратно в тупой повторитель. Для этого они придумали три способа которые собственно называются режимами работы NLB:
- Unicast - в этом режиме они просто генерируют новый mac адрес и присваивают его сразу всем сетевым интерфейсам участвующим в балансировке. Похеру что люди писавшие стандарты прилагали столько усилий чтобы сделать mac адреса уникальными. В такой ситуации свитч понимает что мак адрес соответсвующий виртуальному IP балансера привязан к нескольким портам и при поступлении пакета отправляет его на все порты.
- Multicast - это уже более стандартизированная штука. Есть пул mac адресов начинающихся с 03-BF (возможно есть и другие префиксы, я оригинал стандарта не читал)
- Multicast + IGMP - это более продвинутая версия предыдущего варианта, которая как вы можете догадаться использует Internet Group Management Protocol. Если в кратце - хосты сами подписываются на широковещательные сообщения по определенному мак адресу.
Итак, NLB добился того что все пакеты дублируются на все интерфейсы одним из перечисленных выше способов. После этого у вас есть возможность отфильтровать какую-то часть из этих пакетов на уровне сетевого стэка, а какую-то оставить на обработку другим хостам. Примерно тоже самое но на английском описано вот в этой статье: The NLB Deployment Reference – All you need to know to implement and deploy Microsoft Network Load Balancing К сожалению нормальной документации по NLB у Microsoft нет. Есть только статьи описывающие структуру меню и дискламеры.
среда, 17 июля 2019 г.
Плёс
В последнее время я в основном все пишу на профессиональные или около профессиональные темы. Думаю самое время смахнуть пыль с рубрики "Путешествия". Так сложилось что в последнее время путешествовать получается все больше по России. Но и в России можно найти очень красивые места.
Сегодня речь пойдет о маленьком (примерно полторы тысячи жителей) городке в Ивановской области, который называется Плёс.

Этот городок покорил меня своеобразным шармом провинциального приволжского городка. Думаю мой родной Ульяновск/Симбирск когда-то был примерно таким же. Но к сожалению сейчас Ульяновск уже совсем другой, а вот Плёс все тот же.

Не смотря на то что Плёс это довольно древний город, сейчас он известен широкому кругу людей не своей историей уходящей в века, а тем что в 19 веке там жил знаменитый художник Исаак Левитан. Кстати жил он там совсем не долго, всего 3 лета. Уже в то время Плёс был "дачным" местом. Сейчас все стало еще хуже - практически все дома на берегу выкуплены москвичами под "дачи". Люди которые бывали в Плесе лет 20 назад говорят что сейчас это совсем другой, туристический город. Хотя я сам находясь там этого не чувствовал.

Я наслаждался этим сочетанием волжских просторов и деревенских пейзажей,

В общем Плёс сейчас занимает одно из первых мест в моем личном рейтинге городов Подмосковья. Всем рекомендую хоть разок туда съездить.
Prox mox
Давеча решил разобраться с prox mox - это вроде open source, должно быть довольно понятно. В общем хер там был - prox mox оказался только формально open source, а на самом деле по духу это microsoft. Формально ребята выложили исходники в репозитории - https://git.proxmox.com/, но кроме самих исходников больше ничего и нету. Есть документация из разряда - маркетинговый булшит, есть документация типа - "руководство начинающего пользователя". И на этом все. Ребята решили - раз уж мы зарабатываем на консалтинге и саппорте - надо предоставить минимум информации. В общем никакого описания внутренней архитектуры, ни каких-то открытых интерфейсов ожидать не приходится. Установка ТОЛЬКО через ISO образы (нет даже элементарных deb/rpm пакетов). Внутри себя он собирает довольно много метрик, и кладет их в RRDTool. Какого-то нормального интерфейса для экспорта этих метрик в Prometheus не предусмотрено. Короче печаль и разочарование. Open source который мы заслужили.
Из хорошего - я нашел довольно годную презентацию от Stefan Hajnoczi - KVM Architecture Overview. После прочтения этой презентации и смежных статей "магии" в моей голове относительно того как работает виртуализация и KVM стало меньше, а понимания больше.
пятница, 12 июля 2019 г.
Сказка про MS SQL и высокую доступность
Подумал я грешным делом а не научится ли мне жить на два датацентра, как это делают взрослые компании. Думаю - MS SQL это же классный сервер, столько бабла за него отдаем. Entrerprise редакция обязана уметь master-master репликацию. Начал читать и тут постигло меня разочарование страшное. Выяснилось что умеет MS SQL в области высокой доступности приблизительно ничего. Ну то есть на уровне MySQL. Это был спойлер, а теперь расскажу по порядку.
Первое что предлагает Microsoft - это высокая доступность по высоким ценам, типичное enterprise решение - покупаешь SAN(СХД или хранилка по нашему), подключаешь ее к двум серверам. На этот шаренный диск ставишь MS SQL Server и получаешь решение которое называется Windows Failover Cluster или SQL Server Failover Cluster Instances (FCIs). По сути база и лог транзакций хранится на шаренном диске, только один SQL Server может принимать/обрабатывать транзакции, второй стоит рядом. Эта архитектура не гарантирует ни высокую доступность ни распределенность. Единственное для чего он годится - это установка обновлений. Ставишь обновления на пассивную ноду, переключаешься - смотришь, если все ок - ставишь обновления на вторую ноду.
Следующее что нам предлагает Microsoft - это Availability Groups(AG). У этой штуки есть еще коммерческое название - Always On Availability Groups. Microsoft не была бы Microsoft если бы не придумала для банальной репликации "продающее" название. Да, к сожалению вы не ослышались - весь этот хваленый Always On это банальная master->slave репликация с кучей ограничений. Дело в том что Always On требует наличия Windows Server Failover Clustering(WSFC), который в свою очередь опирается на Active Directory и требует чтобы все сервера входящие в WSFC находились в одном домене. Отсюда вытекает интересное следствие - Availability Group также должна находится в одном домене, соответсвенно использовать Availability Group для репликации между серверами находящимися в разных датацентрах становится практически невозможно (только если вы не хотите растянуть один домен на два датацентра, а вы скорее всего не хотите этого делать). Еще Availability Group не поддерживает больше 8 реплик (даже в Enterprise редакции). Ну и естественно Availability Group не поддерживает master-master репликацию.
Так что же умеет Availability Group ? Умеет перенаправлять read-only траффик на реплику. Причем для того чтобы это работало само приложение должно указать при подключении флаг - ApplicationIntent=ReadOnly. То есть коннекты должны быть разделены на read only и read-write на уровне приложения, а это значит что неподготовленное приложение вы не сможете просто так отмасштабировать на чтение. Потребуется рефакторинг. Отдельно стоит рассказать как происходит разделение траффика на read/write. Если вы подключаетесь к Availability Group Listener то вы подключитесь к primary replica (SQL Server master) и SQL Server отвечает за то чтобы знать топологию AG и если в нем имеется нода в состоянии synchronized настроенная для приема read-only запросов, то SQL Server отправляет клиенту параметры для прямого подключения к read-only серверу. Такой редирект на уровне MS SQL протокола поддерживают далеко не все клиенты.
Еще AG умеет реплицироваться синхронно и асинхронно. Умеет auto failover, но только если:
- Используется синхронный режим репликации
- Реплика на которую мы планируем failover находится в состоянии synchronized
- Windows Server Failover Clustering(WSFC) имеет кворум.
- Autofailover настроен должным образом
В общем у меня не получилось придумать сценария при котором автоматическое переключение могло сработать как надо. WSFC по сути отвечает за синхронизацию на уровне серверов, и если на уровне серверов связи нет(нет кворума) - то автопереключение работать не будет. То есть при физическом отказе сервера сказки не случится. А зачем тогда весь этот цирк с конями если он работает только во время плановых учений ?
При использовании асинхронного режима оно умеет только в ручную переключать master на одну из реплик с частичной потерей данных, причем про частичную потерю данных говорится при каждом упоминании. Чтобы все сразу воодушевились - как здорово просрать данные. Давай немедленно использовать асинхронную репликацию. Причем как при ее использовании данные не просрать не сказано. К примеру тот же MySQL лет 10 как умееет failover без потери данных при асинхронной репликации.
Отдельно стоит рассказать о взаимоотношениях между WSFC и AG. Как я уже сказал AG опирается в своей работе на WSFC. WSFC в свою очередь отвечает за мониторинг состояния SQL Server запущенного на локальной машине и за поддержание связности с другими серверами входящими в WSFC кластер. Мониторинг состояния SQL сервера сделан в стиле Microsoft - через shared memory. Есть процесс RHS.exe который шарит память с SQL Server, они там по очереди timestamp обновляют. Не обновил timestamp - значит умер. Идея здравая, но зачем это через shared memory делать ??
Следующий интересный момент - как происходит failover. Для подключения к Availability Group используется так называемый Availability Group Listener. Listener состоит из Network Name Resource про который я уже писал и порта. Когда происходит failover все коннекты обрубаются, и клиенты начинают переподключаться. Сколько-то retry делается внутри SQL клиента, но также рекомендуется выполнять переподключения в приложении. И в общем после какого-то количества повторов клиенты подключаются к новому серверу.
На этом казалось бы уже длинная сказка про отсутсвие вменяемого HA setup-а должна подойти к концу. Но надо рассказать про еще одного героя - Distributed Availability Group. DAG появился как костыль, позволяющий строить cross-site setup (инсталяции работающие более чем в одном датацентре). DAG позволяет объединить 2 или более AG в единую Availability Group. По сути позволяет реплицировать лог транзакций из primary replica одной AG в primary replica другой AG, а та уже в свою очередь реплицирует его на свои slave-ы. То есть DAG позволяет построить многоранговую сеть репликации и обойти ограничение на 8 slave-ов. Автоматически реплицироваться она не умеет, все это придется делать руками.
В общем как-то так. Никакой master-master репликации там близко нет.
Network Name Resource
За что я не люблю Microsoft - так это за отсутствие нормальной документации. Ну то есть формально какая-то документация всегда есть - но это маркетинговая документация. Цель этой документации - не объяснить как работает та или иная технология, а напичкать тебя маркетинговыми названиями и аббревиатурами. Сделать так чтобы ты запутался в бесконечных уровнях абстракции. Сделать каждый уровень абстракции еще более абстрактным чем предыдущий. Что в купе с отсутствием информации о реальной стороне вещей порождает карго-культ технологий Microsoft. В итоге понимание того как реально работает та или иная технология, на какие протоколы она опирается, какие алгоритмы использует приходится черпать из того раздела документации где описываются известные проблемы.
Возьмем как пример - Network Name Resource. Я профильтровал через свой мозг десятки страниц маркетингового булшита прежде чем найти вот эту страницу - https://techcommunity.microsoft.com/t5/Failover-Clustering/DNS-Registration-with-the-Network-Name-Resource/ba-p/371482 Прочитав ее я понял что Network Name - это не имя сети, как можно было заключить из дословного перевода , а по сути service discovery сделанный через DNS. Ты создаешь Network Name Resource (DNS имя), привязываешь к нему ресурсы на которые оно должно показывать либо статические IP. Если ты привязал к доменному имени ресурсы(сервера) то их текущие IP адреса будут определены через DHCP. Как только эти сервера появляются в сети - DNS сервер начинает отдавать IP адреса этих серверов при запросе на resolve этого доменного имени.
Нет, это конечно похвально что в Microsoft изобрели service discovery еще до того как это стало main stream-ом, но блин - это мертворожденное решение. Все знают про DNS cache, а значит этот service discovery заведомо обречен на то чтобы лажать. Всегда будет какая-то задержка. Клиент не может каждый раз резолвить DNS имя при его использовании.
понедельник, 1 июля 2019 г.
What makes a leader? by Daniel Goleman
Иногда со мной так бывает, прочитаешь какую-нибуть книгу/статью и понимаешь что - "блин, я это знал". Но знал интуитивно, теперь знаю что большие дядьки пишущие книги про менеджмент думают приблизительно также и что у того что мне подсказывала интуиция есть научная основа.
Не смотря на избитый заголовок, What makes a leader? на удивление годная статья. Если в кратце - хороших лидеров отличает вещь которую сейчас принято называть эмоциональным интеллектом. В нем выделяют 5 компонентов.
- self-awareness(самоосознание,самоанализ) - способность понимать свои сильные и слабые стороны, трезво оценивать свои силы.
- self-regulation (саморегуляция) - способность управлять своими эмоциями, способность нивелировать влияние своих слабых сторон.
- motivation - это слово не нуждается в переводе, оно давно затерто до дыр. Но вопреки устоявшемуся мнению - мотивация это способность оставаться мотивированным без привлечения внешних мотиваторов (деньги, престиж, должность). То есть этим суперскилом обладают только те люди для которых мотиватором является сам факт достижения результата, люди которые кайфуют от фразы - "я сделал это, я нереально крут!"
- empathy - это способность понимать эмоции других людей. Это не про сопереживание/жалость к другим людям, а про способность понимать эмоции людей и принимать в расчет этот фактор наряду с другими факторами.
- social skills - это способность быстро налаживать взаимоотношения с другими людьми, способность к нетворкингу, и способность использовать эти отношения для решения своих задач.
Подписаться на:
Сообщения (Atom)